In Windows, When We delete a file, It goes to "Recycle Bin" and from there we can again recover it using "restore", So its not irrevocably deleted.
So, We want to permanently delete it, we usually can use "Shift + Delete"
Similarly, Analogy is when we use shredder in real life to shred paper and then throw shredded pieces in trash instead of throwing crumpled paper directly in trash bin.
For Example - "shred -u foo.txt"
Description
shred is a program that will overwrite your files in a way that makes them very difficult to recover by a third party.
Normally, when you delete a file, that portion of the disk is marked as being ready for another file to be written to it, but the data is still there. If a third party were to gain physical access to your disk, they could, using advanced techniques, access the data you thought you had deleted.
The analogy is that of a paper shredder. If you crumple up a piece of paper and throw it in the trash can, a third party could come along, root through your trash, and find your discarded documents. If you want to destroy the document, it's best to use a paper shredder. Or burn it, I suppose, but that's not always practical in a typical office.
The way that shred accomplishes this type of destruction digitally is to overwrite (over and over, repeatedly, as many times as you specify) the data you want to destroy, replacing it with other (usually random) data. Doing this magnetically destroys the data on the disk and makes it highly improbable that it can ever be recovered.
It also Allows ScreenGrab/Screenshot Capture from Another Device
You can connect upto 4 Devices
Its a "Microsoft Garage" Project
It does not Extend Screen or Duplicate it or Project it - Like "Windows + P" -> "Connect to Wireless Device"
Its Almlost like a KVM Switch but in Software - It does not share Screens (It Shares Files, though)
KVM is - Keyboard, Video , Mouse - Switch (Hardware Fob)
Journey
The Garage was created in 2009 by a small group of employees to work together on side projects. By 2011, what started as a mini-rebellion had grown into over 3,000 employees around the world, all hacking, building, and tinkering. Truong Do, Microsoft Dynamics AX developer and creator of Mouse without Borders, was part of the early movement, and Mouse without Borders is his side project.
Originally released in September 2011 to accolades from top press outlets, Mouse without Borders has achieved millions of downloads and continues to be hugely popular in the developer community at large. Mouse without Borders is one of the first Garage projects to be released to the public, and almost seven years later is still a top search term for the Garage.
Truong continues to work as a Microsoft employee and remains dedicated to keeping Mouse without Borders ready to go on the latest Windows operating systems.
From its humble roots as side project in the early days of the Garage, Mouse without Borders has stood the test of time and proven that a small project can have big impact.
Consider the following code with your current instruction pointer (the line that will be executed next, indicated by ->) at the f(x) line in g(), having been called by the g(2) line in main():
public class testprog {
static void f (int x) {
System.out.println ("num is " + (x+0)); // <- STEP INTO
}
static void g (int x) {
-> f(x); //
f(1); // <----------------------------------- STEP OVER
}
public static void main (String args[]) {
g(2);
g(3); // <----------------------------------- STEP OUT OF
}
}
If you were to step into at that point, you will move to the println() line in f(), stepping into the function call.
If you were to step over at that point, you will move to the f(1) line in g(), stepping over the function call.
Another useful feature of debuggers is the step out of or step return. In that case, a step return will basically run you through the current function until you go back up one level. In other words, it will step through f(x) and f(1), then back out to the calling function to end up at g(3) in main().
Load resource from the application root folder
"file:data.txt"
Load resource from classpath
classpath:data.txt"
Load resource from the filesystem
file:///c:/temp/filesystemdata.txt"
Load resource from URL
https://testsite.com/data.txt"
where host is the fully qualified domain name of the system on which the path is accessible, and path is a hierarchical directory path of the form directory/directory/.../name. If host is omitted, it is taken to be "localhost", the machine from which the URL is being interpreted. Note that when omitting host, the slash is not omitted (while "file:///foo.txt" is valid, "file://foo.txt" is not, although some interpreters manage to handle the latter).
RFC 3986 includes additional information about the treatment of ".." and "." segments in URIs.
public ReloadableResourceBundleMessageSourceWrapper reloadableResourceBundleMessageSource(String externalFilePath) {
ReloadableResourceBundleMessageSource reloadableResourceBundleMessageSource = new ReloadableResourceBundleMessageSource
reloadableResourceBundleMsgSource.setBasename(externalFilePath);//Full Filepath of Properties/XML , file: or classpath: or relativePath
reloadableResourceBundleMsgSource.setCacheSeconds(60);//After 60 Seconds, It tries to validate Cache again - Tries to read file againreturn reloadableResourceBundleMsgSource;
}
Parameters:code the message code to look up, e.g. 'calculator.noRateSet'.
MessageSource users are encouraged to base message names on qualified classor package names, avoiding potential conflicts and ensuring maximum clarity.
args an array of arguments that will be filled in for params withinthe message (params look like "{0}", "{1,date}", "{2,time}" within a message),or null if nonelocale the locale in which to do the lookupReturns:the resolved message (never null)
Throws:NoSuchMessageException - if no corresponding message was found
Set a single basename, following the basic ResourceBundle convention of not specifying file extension or language codes.
void setBasename(String basename);
Set an array of basenames, each following the basic ResourceBundle convention of not specifying file extension or language codes.
About message resource keep note: A plain path will be relative to the current application context. A "classpath:" URL will be treated as classpath resource. A "file:" URL will load from an absolute file system path. Any other URL, such as "http:", is possible too.
//Set the number of milliseconds to cache loaded properties files.
void setCacheMillis(long cacheMillis)
//Set the number of seconds to cache loaded properties files.
void setCacheSeconds(int cacheSeconds)
In 2015-2016, we redesigned a monolithic application into Microservices and chose the Spring Cloud Netflix as the foundation.
Quoting the docs:
(Spring Cloud Netflix) provides Netflix OSS integrations for Spring Boot apps through autoconfiguration and binding to the Spring Environment and other Spring programming model idioms.
Overtime, we gained more familiarity with the framework, and I even contributed some pull requests. I thought I knew enough until I started looking into Eureka redundancy and failover. A quick proof of concept didn’t work and as I dug more, I came across other poor souls scouring the internet for similar information. Unfortunately, there wasn’t much to find. To their credit, the Spring Cloud documentation is fairly good, and there’s also a Netflix Wiki, but none went into the level of detail I was looking for. This post attempts to bridge that gap. I assume some basic familiarity with Eureka and service discovery, so if you’re new to those, come back after having read the Spring Cloud documentation.
Eureka has two basic components, server and client. Quoting the Netflix Wiki:
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers. We call this service, the Eureka Server. Eureka also comes with a Java-based client component, the Eureka Client, which makes interactions with the service much easier. The client also has a built-in load balancer that does basic round-robin load balancing.
A Eureka client application is referred to as an instance. There’s a subtle difference between a client application and Eureka client; the former is your application while the latter is a component provided by the framework.
Netflix designed Eureka to be highly dynamic. There are properties, and then there are properties that define intervals after which to look for changes in the first set of properties. This is a common paradigm, meaning most of these properties can be changed at runtime, and are picked up in the next refresh cycle. For example, the URL that the client uses to register with Eureka can change and that is picked up after 5min (configurable by eureka.client.eurekaServiceUrlPollIntervalSeconds). Most users will not need such dynamic updates but if you do, you can find all the configuration options as follows:
For Eureka server config: org.springframework.cloud.netflix.eureka.server.EurekaServerConfigBean that implements com.netflix.eureka.EurekaServerConfig. All properties are prefixed by eureka.server.
For Eureka client config: org.springframework.cloud.netflix.eureka.EurekaClientConfigBean that implements com.netflix.discovery.EurekaClientConfig. All properties are prefixed by eureka.client.
For Eureka instance config: org.springframework.cloud.netflix.eureka.EurekaInstanceConfigBean that implements (indirectly) com.netflix.appinfo.EurekaInstanceConfig. All properties are prefixed by eureka.instance.
Refer to Netflix Wiki for further architectural details.
An instance is identified in Eureka by the eureka.instance.instanceId or, if not present, eureka.instance.metadataMap.instanceId. The instances find each other using eureka.instance.appName, which Spring Cloud defaults to spring.application.name or UNKNOWN, if the former is not defined. You’ll want to set spring.application.name because applications with the same name are clustered together in Eureka server. It’s not required to set eureka.instance.instanceId, as it defaults to CLIENT IP:PORT, but if you do set it, it must be unique within the scope of the appName. There’s also a eureka.instance.virtualHostName, but it’s not used by Spring, and is set to spring.application.name or UNKNOWN as described above.
If registerWithEureka is true, an instance registers with a Eureka server using a given URL; then onwards, it sends heartbeats every 30s (configurable by eureka.instance.leaseRenewalIntervalInSeconds). If the server doesn’t receive a heartbeat, it waits 90s (configurable by eureka.instance.leaseExpirationDurationInSeconds) before removing the instance from registry and there by disallowing traffic to that instance. Sending heartbeat is an asynchronous task; if the operation fails, it backs off exponentially by a factor of 2 until a maximum delay of eureka.instance.leaseRenewalIntervalInSeconds * eureka.client.heartbeatExecutorExponentialBackOffBound is reached. There is no limit to the number of retries for registering with Eureka.
The heartbeat is not the same as updating the instance information to the Eureka server. Every instance is represented by an com.netflix.appinfo.InstanceInfo, which is a bunch of information about the instance. The InstanceInfo is sent to the Eureka server at regular intervals, starting at 40s after startup (configurable by eureka.client.initialInstanceInfoReplicationIntervalSeconds), and then onwards every 30s (configurable by eureka.client.instanceInfoReplicationIntervalSeconds).
If eureka.client.fetchRegistry is true, the client fetches the Eureka server registry at startup and caches it locally. From then on, it only fetches the delta (this can be turned off by setting eureka.client.shouldDisableDelta to false, although that’d be a waste of bandwidth). The registry fetch is an asynchronous task scheduled every 30s (configurable by eureka.client.registryFetchIntervalSeconds). If the operation fails, it backs off exponentially by a factor of 2 until a maximum delay of eureka.client.registryFetchIntervalSeconds * eureka.client.cacheRefreshExecutorExponentialBackOffBound is reached. There is no limit to the number of retries for fetching the registry information.
The client tasks are scheduled by com.netflix.discovery.DiscoveryClient, which Spring Cloud extends in org.springframework.cloud.netflix.eureka.CloudEurekaClient.
Why Does It Take So Long to Register an Instance with Eureka?Permalink
The first heartbeat happens 30s (described earlier) after startup so the instance doesn’t appear in the Eureka registry before this interval.
Server Response Cache
The server maintains a response cache that is updated every 30s (configurable by eureka.server.responseCacheUpdateIntervalMs). So even if the instance is just registered, it won’t appear in the result of a call to the /eureka/apps REST endpoint. However, the instance may appear on the Eureka Dashboard just after registration. This is because the Dashboard bypasses the response cache used by the REST API. If you know the instanceId, you can still get some details from Eureka about it by calling /eureka/apps/<appName>/<instanceId>. This endpoint doesn’t make use of the response cache.
So, it may take up to another 30s for other clients to discover the newly registered instance.
Client Cache Refresh
Eureka client maintain a cache of the registry information. This cache is refreshed every 30s (described earlier). So, it may take another 30s before a client decides to refresh its local cache and discover other newly registered instances.
LoadBalancer Refresh
The load balancer used by Ribbon gets its information from the local Eureka client. Ribbon also maintains a local cache to avoid calling the client for every request. This cache is refreshed every 30s (configurable by ribbon.ServerListRefreshInterval). So, it may take another 30s before Ribbon can make use of the newly registered instance.
In the end, it may take up to 2min before a newly registered instance starts receiving traffic from the other instances.
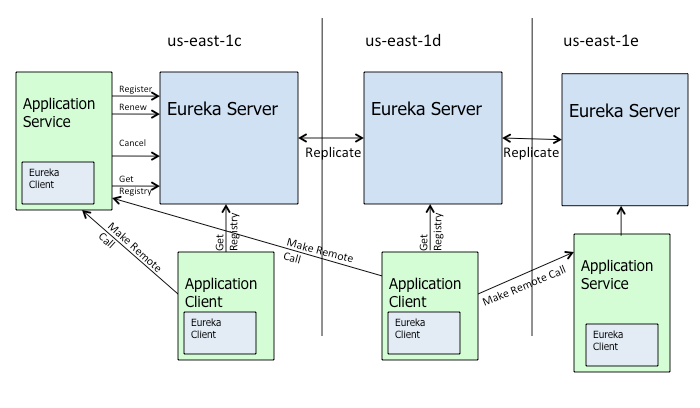
The Eureka server has a peer-aware mode, in which it replicates the service registry across other Eureka servers, to provide load balancing and resiliency. Peer-aware mode is the default so a Eureka server also acts as a Eureka client and registers to a peer on a given URL. This is how you should run Eureka in production but for demo or proof of concepts, you can run in standalone mode by setting registerWithEureka to false.
When the eureka server starts up it tries to fetch all the registry information from the peer eureka nodes. This operation is retried 5 times for each peer (configurable by eureka.server.numberRegistrySyncRetries). If for some reason this operation fails, the server does not allow clients to get the registry information for 5min (configurable by eureka.server.getWaitTimeInMsWhenSyncEmpty).
Eureka peer awareness brings in a whole new level of complication by introducing a concept called “self-preservation” (can be turned off by setting eureka.server.enableSelfPreservation to false). In fact, when looking online, this is where I saw most people tripping on. From Netflix Wiki:
When the Eureka server comes up, it tries to get all of the instance registry information from a neighboring node. If there is a problem getting the information from a node, the server tries all of the peers before it gives up. If the server is able to successfully get all of the instances, it sets the renewal threshold that it should be receiving based on that information. If any time, the renewals falls below the percent configured for that value, the server stops expiring instances to protect the current instance registry information.
The math works like this: If there are two clients registered to a Eureka instance, each one sending a heartbeat every 30s, the instance should receive 4 heartbeats in a minute. Spring adds a lower minimum of 1 to that (configurable by eureka.instance.registry.expectedNumberOfRenewsPerMin), so the instance expects to receive 5 heartbeats every minute. This is then multiplied by 0.85 (configurable by eureka.server.renewalPercentThreshold) and rounded to the next integer, which brings us back to 5 again. If anytime there are less than 5 heartbeats received by Eureka in 15min (configurable by eureka.server.renewalThresholdUpdateIntervalMs), it goes into self-preservation mode and stops expiring already registered instances.
Eureka server makes an implicit assumption that the clients are sending their heartbeat at a fixed rate of 1 every 30s. If two instances are registered, the server expects to receive (2 * 2 + 1 ) * 0.85 = 5 heartbeats every minute. If the renewal rate drops below this value, the self-preservation mode is activated. Now, if the clients are sending heartbeats much faster (say, every 10s), the server receives 12 heartbeats per minute and keeps receiving 6/min even if one of the instances goes down. Thus, the self protection mode is not activated even though it should be. This is why it’s not advisable to change eureka.client.instanceInfoReplicationIntervalSeconds. You can instead tinker with eureka.server.renewalPercentThreshold if you must.
Eureka peers don’t count towards the expected number of renewals, but the heartbeats from them is considered within the number of renewals received last minute. In peer-aware mode, the heartbeats can go to any Eureka instance; this is important when running behind a load balancer or as a Kubernetes service, where the heartbeats are sent in Round-robin mode (usually) to each instance.
The Eureka server doesn’t come out of self-preservation mode until the renewals rise above the threshold. This may cause the clients to get the instances that do not exist anymore. Refer to Understanding Eureka Peer to Peer Communication
One more thing: There is a gotcha with running more than one Eureka server on the same host. Netflix code (com.netflix.eureka.cluster.PeerEurekaNodes.isThisMyUrl) filters out the peer URLs that are on the same host. This may have been done to prevent the server registering as its own peer (I’m guessing here) but because they don’t check for the port, peer awareness doesn’t work unless the Eureka hostnames in the eureka.client.serviceUrl.defaultZone are different. The hacky workaround for this is to define unique hostnames and then map them to 127.0.0.1 in the /etc/hosts file (or its Windows equivalent). Spring Cloud doc talks about this workaround but fails to mention why it’s needed. Now you know.
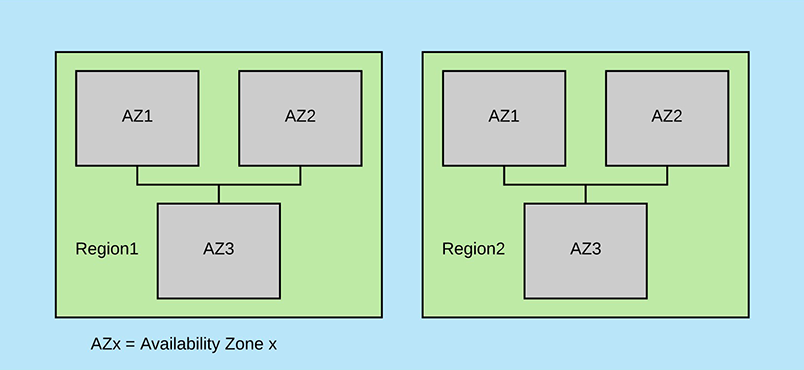
Eureka was designed to run in AWS and uses many concepts and terminologies that are specific to AWS. Regions and Zones are two such things. From AWS doc:
Amazon EC2 is hosted in multiple locations world-wide. These locations are composed of regions and Availability Zones. Each region is a separate geographic area. Each region has multiple, isolated locations known as Availability Zones … Each region is completely independent. Each Availability Zone is isolated, but the Availability Zones in a region are connected through low-latency links.
The Eureka dashboard displays the Environment and Data center. The values are set to test and default, respectively, from org.springframework.cloud.netflix.eureka.server.EurekaServerBootstrap by using com.netflix.config.ConfigurationManager. There are various lookups and fallbacks, so if for some reason you need to change those, refer to the source code of the aforementioned classes.
The Eureka client prefers the same zone by default (configurable by eureka.client.preferSameZone). From com.netflix.discovery.endpoint.EndpointUtils.getServiceUrlsFromDNS Javadoc:
Get the list of all eureka service urls from DNS for the eureka client to talk to. The client picks up the service url from its zone and then fails over to other zones randomly. If there are multiple servers in the same zone, the client once again picks one randomly. This way the traffic will be distributed in the case of failures.
Ticket spring-cloud-netflix#203 is open as of this writing where several people talk about regions and zones. I’ve not verified any of that so I can’t comment on how regions and zones work with Eureka.